Введение
Это четвертая и последняя статья серии, посвященной установке и настройке большого Linux-кластера. Целью данной серии является объединение в одном месте последней информации из разнообразных общедоступных источников о создании работающего Linux-кластера из множества отдельных частей аппаратного и программного обеспечения. В этих статьях не описываются основы проектирования нового большого Linux-кластера, а лишь предоставляются ссылки на соответствующие справочные материалы и Redbooks™ по общей архитектуре.
Данная серия статей предназначена для использования системными разработчиками и системными инженерами при планировании и внедрении Linux-кластера при помощи интегрированной среды IBM eServer Cluster 1350 (ссылки на дополнительную информацию по данной среде приведены в разделе "Ресурсы"). Некоторые статьи могут быть полезны администраторам как в качестве учебных материалов, так и при использовании в процессе эксплуатации кластера. Каждая часть данной серии статей ссылается на один и тот же пример установки.
В первой части данной серии приведены подробные инструкции по установке аппаратного обеспечения кластера. Во второй части рассматриваются следующие после конфигурирования оборудования действия: установка программного обеспечения при помощи программы управления системами IBM Cluster Systems Management (CSM) и установка узлов.
Третья часть и эта статья описывают систему хранения данных кластера, включая установку и настройку аппаратного обеспечения системы хранения данных, а также настройку файловой системы IBM с совместным доступом General Parallel File System (GPFS). В третьей части рассмотрена архитектура системы хранения данных, подготовка аппаратного обеспечения и подробная информация по установке Storage Area Network. В данной, четвертой и последней, части серии подробно рассматриваются специфические вопросы CSM, относящиеся к системе хранения данных нашего примера кластера, в частности, установка узлов для системы хранения данных и настройка GPFS-кластера.
Детализация специфики установки узла
В данном разделе детализируются специфические вопросы управления сервером кластера (cluster server management - CSM), связанные с системой хранения данных примера кластера. К ним относятся установка GPFS-кода на каждом узле и настройка адаптеров Qlogic для узлов системы хранения. Обращаем внимание на то, что эта настройка не обязательно должна выполняться с использованием CSM; ее можно сделать и вручную. В примере данной статьи используется CSM для практически полной автоматизации установки нового сервера, в том числе и сервера хранения данных.
Обзор архитектуры
Перед прочтением данного раздела полезно повторить материал раздела "Общая архитектура кластера" из первой статьи данной серии. Также полезно просмотреть раздел по архитектуре системы хранения данных в третьей статье. Понимание архитектуры обеспечит необходимый контекст для наилучшего использования приведенной ниже информации.
Установка узлов системы хранения данных в правильном порядке
Установка в нужном порядке является обязательным условием для устранения проблемы переполнения ROM, описанной позже, поскольку используемые в данной конфигурации системы xSeries™ 346 не имеют карт RAID 7K. Выполните следующие действия в указанном порядке:
- Выполните команду
csmsetupks -vxn <nodename> на управляющем сервере.
- Отключите сервер системы хранения данных от SAN, для того чтобы избежать установки операционной системы на SAN-дисках, которые обнаруживаются первыми.
- Выполните команду
installnode -vn <nodename> на управляющем сервере.
- Нажмите F1 в консоли после перезагрузки узла системы хранения данных для входа в BIOS.
- Перейдите в раздел Start Options и измените PXEboot с
disabled на enabled for planar ethernet 1.
- Перезагрузите узел; начнется установка.
- Следите за установкой через терминальный сервер; пусть узел полностью завершит начальную загрузку.
- Зарегистрируйтесь на узле и просмотрите log-файл установки csm
log /var/log/csm/install.log.
- Перезагрузите узел после завершения задания post reboot.
- Нажмите клавишу F1 на консоли после перезагрузки узла для входа в BIOS.
- Перейдите в раздел Start Options и измените PXEboot на
disabled.
- Подключите SAN-кабели и подождите завершения начальной загрузки узла.
- Настройте пути к диску при помощи MSJ, как описано в разделе "Настройка путей к дискам и распределения нагрузки".
Организация беспарольного доступа к учетной записи root между узлами
GPFS требует, чтобы все узлы в GPFS-кластере были способны обращаться друг к другу, используя root ID без предоставления пароля. GPFS использует этот межузловой доступ, чтобы разрешить любому узлу в GPFS-кластере выполнять соответствующую команду на других узлах. В приведенном в этой статье примере для предоставления доступа используется ssh (secure shell), однако можно использовать также rsh (remote shell). Для этого создайте ключ, относящийся ко всему кластеру, и соответствующие конфигурационные файлы, которые распределите при помощи CSM, выполнив следующие действия:
- Создайте два новых каталога в
/cfmroot/root/.ssh и /cfmroot/etc/ssh.
- Создайте пару RSA-ключей, открытый и закрытый ключи для аутентификации, выполнив команду
ssh-keygen -b 1024 -t rsa -f /cfmroot/etc/ssh/ssh_host_rsa_key -N "" -C "RSA_Key" |
- Создайте пару DSA-ключей, открытый и закрытый ключи для аутентификации, выполнив команду
ssh-keygen -b 1024 -t dsa -f /cfmroot/etc/ssh/ssh_host_dsa_key -N "" -C "DSA_Key" |
- Создайте файл авторизации, содержащий открытые ключи, как показано ниже. Это файл, который SSH использует для определения необходимости запроса пароля.
cat /root/.ssh/id_rsa.pub > /cfmroot/root/.ssh/authorized_keys2
cat /root/.ssh/id_dsa.pub >> /cfmroot/root/.ssh/authorized_keys2
cat /cfmroot/etc/ssh/ssh_host_rsa_key.pub >> /cfmroot/root/.ssh/authorized_keys2
cat /cfmroot/etc/ssh/ssh_host_dsa_key.pub >> /cfmroot/root/.ssh/authorized_keys2 |
- Отключите поддержку CSM файла
known_hosts, как показано ниже. Этот файл содержит имена хостов. Если имя хоста имеется в файле, SSH не запрашивает у пользователя подтверждения подключения. CSM пытается поддерживать данный файл, но в стационарной среде кластера с беспарольным root-доступом это может быть помехой.
stopcondresp NodeFullInstallComplete SetupSSHAndRunCFM
startcondresp NodeFullInstallComplete RunCFMToNode
perl -pe 's!(.*update_known_hosts.*)!#$1!' -i /opt/csm/csmbin/RunCFMToNode |
- Сгенерируйте файл
known_hosts для системы. Лучше всего сделать это путем создания сценария, как показано ниже. Выполните сценарий и направьте вывод информации в /cfmroot/root/.ssh/known_hosts.
#!/bin/bash
RSA_PUB=$(cat "/cfmroot/etc/ssh/ssh_host_rsa_key.pub")
DSA_PUB=$(cat "/cfmroot/etc/ssh/ssh_host_dsa_key.pub")
for node in $(lsnodes); do
ip=$(grep $node /etc/hosts | head -n 1 | awk '{print $1}')
short=$(grep $node /etc/hosts | head -n 1 | awk '{print $3}')
echo $ip,$node,$short $RSA_PUB
echo $ip,$node,$short $DSA_PUB
done |
Этот пример сценария работает для одиночного интерфейса. Вы можете просто изменить его, чтобы разрешить беспарольный доступ для нескольких интерфейсов. Обсуждение формата файла known_hosts выходит за рамки данной статьи, но полезно использовать разделенные запятыми имена хостов в отдельных строках.
- Разрешите беспарольный доступ, создав ссылки на сгенерированные ключи, как показано ниже.
cd /cfmroot/root/.ssh
ln -s ../../etc/ssh/ssh_host_dsa_key id_dsa
ln -s ../../etc/ssh/ssh_host_dsa_key.pub id_dsa.pub
ln -s ../../etc/ssh/ssh_host_rsa_key id_rsa
ln -s ../../etc/ssh/ssh_host_rsa_key.pub id_rsa.pub |
- Убедитесь, что данная конфигурация устанавливается на каждую систему, перед первой перезагрузкой операционной системы. CSM не гарантирует порядок действий после установки, поэтому, если какое-либо задание зависит от наличия данной конфигурации, оно может не выполниться. Оно может также выполниться успешно, но выдать ошибку несовместимости. Например, в случае, если у вас есть послеустановочный сценарий, и вам необходимо добавить узел к GPFS-кластеру и смонтировать все файловые системы GPFS. Одним из способов избежать такого поведения могло бы быть создание tar-архива всех созданных здесь файлов и их разархивирование при помощи сценария CSM, выполняющегося после установки до перезагрузки.
Определение относящихся к GPFS CSM-групп
Для данного примера определяются две главных CSM-группы, использующиеся во время настройки GPFS, как показано ниже.
StorageNodes, включающая только те узлы, которые подключаются напрямую к SAN, например, nodegrp -w "Hostname like 'stor%'" StorageNodes.
NonStorageNodes, включающая только те узлы, которые являются частью GPFS-кластера, например, nodegrp -w "Hostname not like 'stor%'" NonStorageNodes.
Эти группы используются во время установки, чтобы гарантировать получение серверами, выполняющими роли узлов системы хранения данных, специфичных бинарных и конфигурационных файлов, которые детально рассмотрены ниже. Обратите внимание на то, что в данном разделе не описывается подробно процедура установки, выполняемая CMS. Инструкции по этой процедуре приведены в первой и второй статьях данной серии.
Обобщенно процесс установки проходит следующие этапы:
- PXE-загрузка/DHCP с сервера установки.
- Установка NFS с сервера установки.
- Сценарии, выполняющиеся до перезагрузки (pre-reboot).
- Перезагрузка.
- Сценарии, выполняющиеся после перезагрузки (post-reboot).
- Передача CFM-файла.
- Послеустановочная настройка CSM.
Изменения конфигурации в данной статье происходят на этапах pre-reboot и передачи CFM-файла.
Установка RPM-файлов GPFS
GPFS требует наличия на каждом члене кластера базового набора установленных RPM-файлов GPFS. В примере использовалась GPFS версии 2.3.0-3. Установка этих RPM представляет собой процесс из двух этапов: установка базовой версии 2.3.0-1 и последующее обновление до 2.3.0-3. Для данной установки использовались следующие RPM-файлы:
- gpfs.base
- gpfs.docs
- gpfs.gpl
- gpfs.msg.en_US
Примечание: Поскольку пример использует GPFS Version 2.3, установка Reliable Scalable Cluster Technology (RSCT) и создание домена одноранговой сети (peer) не требуется. Версии GPFS до Version 2.3 требовали выполнения этих действий вручную.
CSM может установить RPM-файлы GPFS различными способами. В данной статье рекомендуется устанавливать RPM на этапе установки базовой операционной системы. CSM предоставляет структуру каталогов установки и обновления, содержащую настроенные RPM-файлы, однако это может работать не очень хорошо в случае первоначальной установки RPM, за которой выполняется обновление этих же RPM, что нужно для GPFS 2.3.0-3.
Одним из альтернативных методов является написание сценариев для CSM (выполняющихся до перезагрузки и после установки), чтобы установить необходимые RPM-файлы. В данном случае скопируйте все RPM-файлы GPFS, включая RPM-файлы обновления, в каталог /csminstall/Linux управляющего сервера. CSM обычно резервирует каталог для данных сценариев /csminstall/csm/scripts/data, который будет монтироваться к узлу во время установки, делая необходимые RPM-файлы доступными через NFS.
Напишите сценарий /csminstall/csm/scripts/installprereboot/install-gpfs.sh для установки GPFS. Вот пример такого сценария:
#! /bin/bash
# Устанавливает набор файлов GPFS и обновляет до последних версий
# Переменная среды CSMMOUNTPOINT устанавливается CSM
DATA_DIR=$CSMMOUNTPOINT/csm/scripts/data
cd $DATA_DIR
rpm -ivh gpfs.*2.3.0-1*.rpm
rpm -Uvh gpfs.*2.3.0-3*.rpm
echo 'export PATH=$PATH:/usr/lpp/mmfs/bin' > /etc/profile.d/gpfs.sh
|
После установки GPFS на сервере хранения данных вы, возможно, также захотите автоматически установить программу FAStT MSJ, что можно сделать в невидимом (не интерактивном) режиме. MSJ используется для настройки адаптеров Qlogic, системы восстановления после сбоев и нескольких каналов передачи, что подробно описывается в разделе по настройке HBA. Установка не основывается на RPM-файлах, поэтому нелегко интегрировать ее в CSM по умолчанию. Для выполнения установки вы можете добавить сценарий в конец установки GPFS для проверки того, является ли узел сервером хранения данных, а также для установки MSJ. Для установки в невидимом режиме используйте команду FAStTMSJ*_install.bin -i silent
Настройка системы восстановления после сбоев Qlogic
Пример кластера использует драйвер Qlogic qla2300 версии 7.01.01 для адаптеров Qlogic QLA 2342. Каждый из узлов в группе узлов системы хранения данных имеет два таких PCI-адаптера. Драйвер qla2300 поставляется стандартно с дистрибутивом Red Hat Enterprise Linux 3 update 4. Однако вы должны выполнить следующие изменения для примера кластера:
- Измените драйвер qla2300 на выполнение восстановления после сбоев. Это позволит вам воспользоваться другим путем к диску и восстановить работоспособность после возникновения сбоя в предпочтительном пути. По умолчанию эта функция отключена.
Первое изменение выполните с использованием сценария, выполняющегося CSM перед перезагрузкой во время установки. Выполняющий это действие сценарий находится в каталоге /csminstall/csm/scripts/installprereboot/. Этот сценарий содержит следующие команды:
#! /bin/bash
# Добавляет строки в /etc/modules.conf для разрешения системы
# восстановления после сбоев для драйверов qla2300
echo "options qla2300 ql2xfailover=1 ql2xmaxsectors=512 ql2xmaxsgs=128" >>
/etc/modules.conf
echo "Updating initrd with new modules.conf set up"
mkinitrd -f /boot/initrd-`uname -r`.img `uname -r`
|
- Установите предпочтительный путь к дискам на каждом хосте соответствующим установленному в каждом контроллере DS4500. Используйте массивы с нечетными номерами, видимые через HBA0, и массивы с четными номерами, видимые через HBA1.
Второе изменение необходимо выполнять вручную после каждой переустановки узла системы хранения данных. Подробно это описано в разделе "Определение конфигурации HBA на серверах хранения данных".
Тонкая настройка GPFS-сети
Пример предлагает добавить несколько строк в файл /etc/sysctl.conf на каждом узле для тонкой настройки GPFS-сети. Это выполняется с использованием установочного сценария CSM, выполняющегося после перезагрузки. Сценарий расположен в каталоге /csminstall/csm/scripts/installpostreboot и содержит следующие строки:
FILE=/etc/sysctl.conf
# Добавляет строки в /etc/sysctl.conf для тонкой настройки GPFS-сети
echo "# CSM added the next 8 lines to the post installation script for
GPFS network tuning" >> $FILE
echo "# increase Linux TCP buffer limits" >> $FILE
echo "net.core.rmem_max = 8388608" >> $FILE
echo "net.core.wmem_max = 8388608" >> $FILE
echo "# increase default and maximum Linux TCP buffer sizes" >> $FILE
echo "net.ipv4.tcp_rmem = 4096 262144 8388608" >> $FILE
echo "net.ipv4.tcp_wmem = 4096 262144 8388608" >> $FILE
echo "# increase max backlog to avoid dropped packets" >> $FILE
echo "net.core.netdev_max_backlog=2500" >> $FILE
# Следующие строки не относятся к настройке GPFS
echo "# Allow Alt-SysRq" >> $FILE
echo "kernel.sysrq = 1" >> $FILE
echo "# Increase ARP cache size" >> $FILE
echo "net.ipv4.neigh.default.gc_thresh1 = 512" >> $FILE
echo "net.ipv4.neigh.default.gc_thresh2 = 2048" >> $FILE
echo "net.ipv4.neigh.default.gc_thresh3 = 4096" >> $FILE
echo "net.ipv4.neigh.default.gc_stale_time = 240" >> $FILE
# Сброс текущих параметров ядра
sysctl -p /etc/sysctl.conf
|
Распределение уровня переносимости GPFS
Уровень переносимости (portability layer - PL) GPFS является зависимым от ядра и должен быть создан отдельно для каждой версии операционной системы вашего кластера. Назначение PL и подробная информация по созданию для примера кластера описаны в разделе "Создание и установка уровня переносимости". Скопируйте бинарные файлы PL в каталог /cfmroot/usr/lpp/mmfs/bin управляющих серверов и назовите их так, чтобы они распределялись только на узлы с определенными версиями ядра в соответствующих группах. Например:
/cfmroot/usr/lpp/mmfs/bin/dumpconv._<nodegroup>
/cfmroot/usr/lpp/mmfs/bin/lxtrace._<nodegroup>
/cfmroot/usr/lpp/mmfs/bin/mmfslinux._<nodegroup>
/cfmroot/usr/lpp/mmfs/bin/tracedev._<nodegroup>
|
Обратите внимание на то, что в большом кластере для уменьшения нагрузки на CFM можно добавить эти четыре файла в специализированный RPM и установить вместе с GPFS, используя метод, приведенный выше для установки RPM-файлов GPFS.
Автоматизация добавления новых узлов в GPFS-кластер
Простой установки GPFS RPMS и уровня переносимости недостаточно для монтирования и настройки файловых систем в GPFS-кластере на новых установленных узлах. Однако масштабирование кластера до больших размеров оправдывает автоматизацию данного шага. Это можно сделать с использованием мониторинговых возможностей CSM для отслеживая завершения установки нового узла и запуска сценария для настройки и монтирования GPFS на новом узле в кластере.
В листинге 1 показан пример сценария, который может быть использован для настройки GPFS. Вам, возможно, понадобится несколько изменить его для вашей конфигурации. В листинге предоставлена основа. Сценарий принимает имя узла (переданное CSM-мониторами), добавляет его в GPFS-кластер и пытается запустить GPFS на этом узле с некоторой тривиальной обработкой ошибок.
Листинг 1. Пример сценария для настройки GPFS
#!/bin/bash
# Сценарий CSM условие/ответ, используемый в качестве ответа на условие
# InstallComplete. Он будет пытаться добавить узел в GPFS-кластер, обрабатывая
# попутно некоторые обычные ошибочные ситуации.
# Выполняются только тривиальные действия; более сложные проблемы должны
# решаться вручную.
# Примечание: требуется файл GPFS gpfs-nodes.list. Этот файл должен содержать список
# всех узлов в GPFS-кластере с подробной информацией клиент/менеджер и
# кворум/отсутствие кворума, подходящей для передачи в команду mmcrcluster.
# Выводимая информация направляется в /var/log/csm/
# Возвращаемые коды ошибок:
# 1 - GPFS уже активен
# 2 - нельзя прочитать файл gpfs-nodes.list
# 3 - отсутствует имя узла в файле gpfs-nodes.list
# 4 - узел является узлом кворума
# 5 - нельзя добавить узел в кластер (mmaddnode выполнилась неудачно)
# 6 - нельзя запустить GPFS на узле (mmstartup выполнилась неудачно)
# укажите месторасположение вашего файла со списком узлов
gpfs_node_list=/etc/gpfs-nodes.list
# укажите интерфейс GPFS, используемый для взаимодействия
gpfs_interface=eth1
PATH=$PATH:/usr/lpp/mmfs/bin # ensure GPFS binaries are in the PATH
log_file=/var/log/csm/`basename $0`.log # log to /var/log/csm/
touch $log_file
# Получить краткое имя узла, установленное RSCT-условием ENV var ERRM_RSRC_NAME
node=`echo $ERRM_RSRC_NAME | cut -d. -f1`
(
[ ! -r "$gpfs_node_list" ] && echo " ** error: cannot read GPFS
node list $gpfs_node_list" && exit 2
echo
echo "--- Starting run of `basename $0` for $node at `date`"
# Является ли узел узлом кворума? Если да, выйти.
quorum_status=`grep $node $gpfs_node_list | cut -d: -f2 | cut -d- -f2`
if [ -n "$quorum_status" ]; then
if [ "$quorum_status" = "quorum" ]; then
echo "** error: this is a quorum node, stopping..."
exit 4
else
node_s=`grep $node $gpfs_node_list | cut -d: -f1`
fi
else
echo "** error: could not find node $node in GPFS node list $gpfs_node_list"
exit 3
fi
# Определить, является ли уже узел частью кластера
if mmlscluster | grep $node >/dev/null; then
# проверить состояние узла
status=`mmgetstate -w $node | grep $node | awk '{print $3}'`
if [ "$status" = "active" ]; then
echo "** error: this node already appears to have GPFS active!"
exit 1
fi
# попытаться удалить узел из кластера
echo "Node $node is already defined to cluster, removing it"
# попытаться запретить интерфейс системы хранения данных на узле
if ssh $node $ifdown $gpfs_interface; then
mmdelnode $node
ssh $node ifup $gpfs_interface
else
echo "** error: could not ssh to $node, or ifdown $gpfs_interface failed"
fi
fi
# попытаться добавить узел в GPFS-кластер
if mmaddnode $node; then
echo "Successfully added $node to GPFS cluster, starting GPFS on $node"
if mmstartup -w $node; then
echo "mmstartup -w $node succeeded"
else
echo "** error: cannot start GPFS on $node, please investigate"
exit 6
fi
else
echo "** error: could not add $node to GPFS cluster"
exit 5
fi
) >>$log_file 2>&1
|
Можно использовать CSM для автоматического запуска сценария, приведенного в листинге 1, после завершения базовой установки операционной системы на узле, так чтобы при ее загрузке автоматически монтировалась файловая система GPFS. Прежде всего, вы должны определить сценарий как механизм ответа в CSM-мониторе. Например: mkresponse -n SetupGPFS -s /path/to/script/SetupGPFS.sh SetupGPFS.
Теперь у вас имеется ответ под названием SetupGPFS, который будет запускать ваш сценарий. Затем вы должны назначить этот ответ CSM-условию по умолчанию NodeFullInstallComplete следующим образом: startcondresp NodeFullInstallComplete SetupGPFS.
Теперь CSM всегда будет автоматически запускать сценарий с управляющего сервера при установке нового узла. На управляющем сервере CSM вы можете увидеть условие NodeFullInstallComplete, связанное с ответом SetupGPFS, при запуске команды lscondresp. Условие или ответ должны быть указаны как Active.
Переполнение адресации ROM
Существует известная проблема с объемом ROM-памяти, доступной на xSeries 346, - ошибки распределения PCI во время загрузки. Сообщения указывают, что системная ROM-память заполнена, и больше нет места для дополнительных адаптеров, использующих память ROM (более подробно в разделе "Ресурсы").
Эта проблема влияет на узлы системы хранения данных, поскольку, если разрешена PXE-загрузка, нет достаточного объема памяти для корректной инициализации PCI-адаптеров Qlogic. Вот один из способов решения данной проблемы:
- Запретите PXE-загрузку на PCI-карте Broadcom, используемой для GPFS-сети. Используя доступную для загрузки возможность diag b57udiag -cmd, выберите устройство, а затем запретите PXE-загрузку.
- Используйте PXE-загрузку для установки узла с использованием CSM, а затем запретите PXE-загрузку для обоих адаптеров, используя BIOS (в порядке, описанном в разделе "Установка узлов системы хранения данных в правильном порядке").
Другое решение проблемы - использование карты RAID 7K в каждой xSeries 346. Она уменьшит объем ROM, используемый SCSI BIOS, и позволит успешно загрузиться Qlogic BIOS даже с разрешенной PXE-загрузкой.
Определение конфигурации HBA на серверах хранения данных
На серверах хранения данных xSeries 346 примера кластера в качестве HBA используются адаптеры модели IBM DS4000 FC2-133 Host Bus Adapter (HBA). Они известны также под названием Qlogic 2342. В примере используется версия встроенной микропрограммы 1.43 и, как упоминалось в предыдущем разделе, драйвер v7.01.01-fo qla2300. Суффикс -fo драйвера обозначает функциональность восстановления после сбоев, которая не является параметром по умолчанию для этого драйвера. Данная функциональность разрешается путем изменения настроек в /etc/modules.conf на каждом узле системы хранения данных. Это действие выполняется при помощи CSM во время установки и описано в разделе "Настройка системы восстановления после сбоев Qlogic".
В следующем разделе описываются действия, необходимые для обновления встроенной микропрограммы и настроек в HBA-адаптерах на каждом сервере хранения данных, а также ручная процедура разрешения функциональности распределения нагрузки между двумя HBA-адаптерами, которую нужно выполнять при каждой повторной установки.
Загрузка микропрограммы HBA
Микропрограмму для HBA-адаптеров FC2-133 можно выполнить с Web-сайта поддержки IBM System x (см. раздел "Ресурсы"). Обновить микропрограмму можно при помощи IBM Management Suite Java, или используя загрузочную дискету и программу flasutil.
Настройка параметров HBA
Для данного примера кластера были изменены (со значений по умолчанию) приведенные ниже настройки HBA-адаптеров. Значения можно найти в файле README, поставляемом вместе с драйвером. Изменения можно сделать в Qlogic BIOS, который вызывается во время загрузки путем нажатия комбинации клавиш <ctrl>-q при запросе либо при помощи служебной программы MSJ. Вот эти настройки:
- Настройки адаптера хоста
- Расширенные настройки адаптера
- LUNs per target: 0
- Enable target reset : Yes
- Port down retry count: 12
Установка IBM Management Suite Java
IBM FAStT Management Suite Java (MSJ) - это Java-приложение с графическим интерфейсом пользователя (GUI), управляющее HBA-адаптерами в управляющих серверах. Его можно использовать для настройки и диагностики. Ссылки на источники для загрузки этой программы приведены в разделе "Ресурсы".
В нашем примере используется CSM для установки MSJ на каждом узле системы хранения данных как части общей установки GPFS. Бинарный файл является частью tar-файла, содержащего RPM-файлы GPFS, который CFS распространяет во время установки CSM-узла. Сценарий, выполняющийся после установки, разархивирует этот tar-файл, который, в свою очередь, запускает сценарий установки, содержащийся внутри tar-файла. В примере используется 32-разрядная версия FAStT MSJ, чтобы обойти потенциальные проблемы, возможные при установке 64-разрядной версии. Пример сценария использует следующую команду для установки MSJ: FAStTMSJ*_install.bin -i silent.
Устанавливается приложение и агент. Обратите внимание на то, что поскольку это 32-разрядная версия MSJ, даже при том, что пример использует не интерактивную установку, код ищет и загружает 32-разрядные версии некоторых библиотек. Следовательно, используйте установленную 32-разрядную версию XFree86-libs, также как 64-разрядную версию, включаемую при базовой 64-разрядной установке. 32-разрядные библиотеки содержатся в файле XFree86-libs-4.3.0-78.EL.i386.rpm, включенном в tar-файл. Установкой этого rpm-файла занимается сценарий install.sh, который затем устанавливает MSJ.
Настройка путей к дискам и распределения нагрузки
Наличие MSJ требуется на каждом узле системы хранения данных для ручной настройки путей к массивам на DS4500 и распределения нагрузки между двумя HBA-адаптерами на каждом компьютере. Если эту настройку не выполнить, по умолчанию все массивы будут доступны через первый адаптер на каждом компьютере (HBA0) и, соответственно, через контроллер A на каждой системе DS4500. Распределяя диски между HBA-адаптерами и, следовательно, между двумя контроллерами на DS4500, вы распределяете нагрузку и улучшаете производительность сервера.
Обратите внимание на то, что настройка распределения нагрузки является ручным процессом и должна выполняться на каждом узле системы хранения данных при каждой его переустановке. Для нашего примера кластера нужно выполнить следующие действия по настройке распределения нагрузки:
- Откройте новое окно на локальном компьютере из вновь установленного сервера с установкой xforwarding (
ssh <nodename> -X).
- В одной сессии запустите
# qlremote.
- В другой сессии запустите
# /usr/FAStT MSJ & для загрузки MSJ GUI.
- В MSJ GUI выделите один из адаптеров в закладке HBA и выберите
Configure. Появится окно, аналогичное изображенному на рисунке 1.
Рисунок 1. Вид MSJ при выборе DS4500
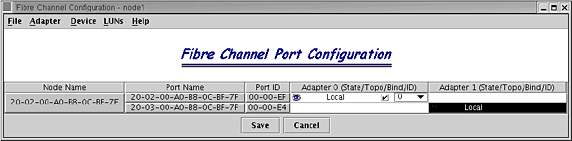
- Для разрешения распределения нагрузки выделите подсистему хранения данных, представляемую после щелчка правой кнопкой мыши на имени узла, и выберите LUNs > Configure LUNs. Появится окно настройки LUN. Вы можете автоматически настроить распределение нагрузки, выбрав Tools > Load Balance. Затем появится окно, аналогичное изображенному на рисунке 2.
Рисунок 2. Вид MSJ при настройке системы восстановления после сбоев
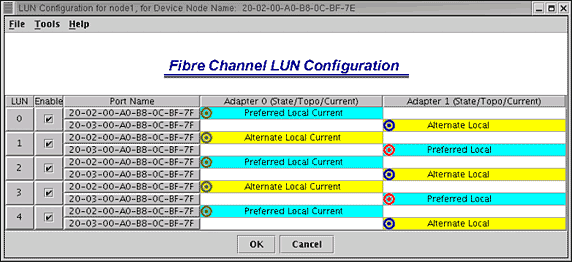
- После настройки логических дисков окно настройки LUN закроется, сохраняя конфигурацию на хост-системе в окне Port Configuration (используется пароль по умолчанию
config). В случае успешного сохранения конфигурации вы увидите подтверждение. Конфигурация сохраняется в виде файла /etc/qla2300.conf. Необходимо добавить новые параметры в строку драйвера qla2300 в файле /etc/modules.conf для индикации существования данного файла и необходимости его использования.
- Вернитесь в окно, в котором был запущен процесс qlremote, и остановите его, используя клавиши
<ctrl>-c. Это важный шаг.
- Для активизации новой конфигурации перезагрузите модуль драйвера qla2300. Этого сделать нельзя, если диск смонтирован на подсистеме Fibre Channel, подключенной к адаптеру, использующему данный драйвер. Настройте драйвер адаптера хоста, который нужно загрузить, через исходный RAM-диск. Конфигурационные данные применятся для резервных дисков при загрузке модуля адаптера во время начальной загрузки. Обратите внимание на то, что необходимо выполнить эту процедуру для сохранения корректной настройки в системе при любом изменении конфигурации модуля адаптера.
Одним из наиболее эффективных способов использования MSJ при установке (когда нужно выполнить настройку распределения нагрузки на более чем одном узле системы хранения данных) является сохранение MSJ в открытом состоянии на одном узле, запуск qlremote на каждом из остальных узлов и использование одной MSJ-сессии для подключения к ним.
Настройка GPFS-кластера
В данном разделе подробно описаны действия по созданию GPFS-кластера. Здесь предполагается, что все узлы были установлены и настроены так, как рассматривалось ранее в данной статье, либо что была выполнена вручную следующая настройка:
- RPM-файлы GPFS установлены на каждом компьютере.
- Переменная PATH изменена и включает каталог с бинарными файлами GPFS.
- Настроен интерфейс системы хранения данных.
- Можно установить ssh-соединение между узлами под пользователем root без ввода пароля.
- Выполнены настройки сети в sysctl.
- NSD-серверы могут видеть SAN-диск.
Подробное описание архитектуры GPFS для примера кластера приведено в разделе "Архитектура системы хранения" в третьей статье данной серии.
Прочтите данный раздел статьи параллельно с документацией по GPFS (см. раздел "Ресурсы"), в частности, следующие материалы:
- Справочник по администрированию и программированию GPFS V2.3, содержащий подробную информацию о многих административных задачах и GPFS-командах.
- Руководство по концепциям, планированию и установке GPFS V2.3, содержащее подробное обсуждение планирования GPFS-кластера и действий при установке нового кластера.
- Руководство по разрешению проблем GPFS V2., содержащее описание действий при устранении проблем и список сообщений об ошибках GPFS.
Создание и установка уровня переносимости
Уровень переносимости (portability layer - PL) GPFS представляет собой набор бинарных файлов, которые должны быть скомпонованы локально из исходных кодов для соответствия ядру Linux и конфигурации компьютера, являющегося частью GPFS-кластера. Для нашего примера кластера это было сделано на одном из узлов системы хранения данных. Полученные в результате файлы были скопированы на каждый узел при помощи CSM и CFM (более подробная информация приведена в разделе "Распределение уровня переносимости GPFS"). Это корректный метод, поскольку все компьютеры имеют одинаковую архитектуру и используют одно и то же ядро. Инструкции по компоновке GPFS PL можно найти в файле /usr/lpp/mmfs/src/README. Для нашего примера кластера процедура состоит из следующих действий:
- Выполните экспорт
SHARKCLONEROOT=/usr/lpp/mmfs/src.
- Выполните команды
cd /usr/lpp/mmfs/src/config, cp site.mcr.proto site.mcr.
- Измените новый файл site.mcr так, чтобы он соответствовал используемой конфигурации. Оставьте следующие строки не закомментированными:
#define GPFS_LINUX
#define GPFS_ARCH_X86_64
LINUX_DISTRIBUTION = REDHAT_AS_LINUX
#define LINUX_DISTRIBUTION_LEVEL 34
#define LINUX_KERNEL_VERSION 2042127
Обратите внимание на то, что символ # не обозначает комментарий.
- Выполните команду
cd /usr/lpp/mmfs/src.
- Создайте GPFS PL, используя команду
make World.
- Скопируйте GPFS PL в каталог
/usr/lpp/mmfs/bin, используя команду make InstallImages. GPFS PL состоит из следующих четырех файлов:
tracedev
mmfslinux
lxtrace
dumpconv
- Скопируйте набор этих файлов, по одному на каждое используемое ядро, в CSM-структуру для распределения при помощи CFM.
Создание GPFS-кластера
В данном примере GPFS-кластер создается при помощи нескольких отдельных действий. Хотя все они не являются необходимыми, это хороший метод работы с различными типами узлов в кластере (узлами системы хранения данных или другими).
Первый шаг - создание кластера, содержащего только узлы системы хранения данных и узел кворума: всего пять узлов. Используйте файлы дескрипторов узла при создании кластера, которые содержат краткое имя хостов интерфейса системы хранения данных всех включаемых узлов, за которым указывается следующая информация:
- Manager или client: Определяет, должен ли узел формировать часть пула, из которого извлекаются менеджеры конфигурации и файловой системы. Пример кластера в этом пуле содержит только узлы хранения данных.
- Quorum или nonquorum: Определяет, должен ли узел учитываться как узел кворума. Узлами кворума в примере кластера являются узлы системы хранения данных и узел разрешения конфликтов
quor001.
Для создания кластера используется следующая команда:
mmcrcluster -n stor.nodes -C gpfs1 -p stor001_s -s stor002_s -r /usr/bin/ssh -R
/usr/bin/scp
|
- Флаг
-C указывает имя кластера.
-p указывает узел сервера первичной конфигурации.
-s указывает узел сервера вторичной конфигурации.
-r указывает полный путь для удаленного командного процессора, используемого GPFS.
-R указывает программу удаленного копирования файлов, используемую GPFS.
Ниже приведен файл-дескриптор узла stor.nodes, используемый в примере:
stor001_s:manager-quorum
stor002_s:manager-quorum
stor003_s:manager-quorum
stor004_s:manager-quorum
quor001_s:client-quorum
|
Используйте записи, аналогичные <nodename>_s:client-nonquorum, на более поздних шагах для всех остальных узлов, добавляемых в кластер, таких как вычислительные узлы, пользовательские узлы и управляющие узлы.
Разрешение unmountOnDiskFail на узлах кворума
Следующим действием является разрешение параметра unmountOnDiskFail на узле разрешения конфликтов с использованием команды mmchconfig unmountOnDiskFail-yes quor001_s. Это предотвращает выдачу отчета о ложных дисковых ошибках менеджеру файловой системы.
Определение сетевых дисков с совместным доступом
Следующим действием является создание дисков, используемых GPFS, при помощи команды mmcrnsd –F disc#.desc. Выполнение этой команды создает глобальное имя для каждого диска, что является необходимым шагом, поскольку диски могут иметь различные имена /dev на каждом узле в GPFS-кластере. Выполните эту команду на всех дисках, используемых для файловой системы GPFS. На данном этапе определите первичный и вторичный NSD-серверы для каждого диска; они используются для операций ввода/вывода (I/O) от имени NSD-клиентов, не имеющих локального доступа к системе хранения данных SAN.
Флаг -F используется для указания файла, содержащего дескрипторы диска для дисков, определяемых как NSD. Для удобства обслуживания в примере кластера выполните этот процесс один раз на LUN, представленных каждой системой DS4500, и один раз на диске сервера разрешения конфликтов. Каждый массив или LUN на каждой системе DS4500 имеет дескриптор в используемых файлах. Ниже приведен пример строки из disk1.desc:
sdc:stor001_s:stor002_s:dataAndMetadata:1:disk01_array01S |
Ниже перечислены поля данной строки по порядку:
- Имя локального диска на первичном NSD-сервере
- Первичный NSD-сервер
- Вторичный NSD-сервер
- Тип данных
- Аварийная группа
- Имя получающегося NSD
Используя описанные выше файлы, определите следующие три аварийные группы в конфигурации:
- Диски в первом контроллере DS4500, то есть
disk01.
- Диски во втором контроллере DS4500, то есть
disk02.
- Диск сервера разрешения конфликтов на узле кворума.
Запуск GPFS
Следующий шаг - запуск GPFS-кластера путем выполнения следующих действий:
- Запустите GPFS на всех NSD-серверах одновременно для предотвращения маркировки NSD как находящихся в неактивном состоянии. Используйте следующую команду:
mmstartup -w stor001_s,stor002_s,stor003_s,stor004_s.
- Запустите GPFS на всех остальных узлах, не являющихся NSD-серверами (в том числе на узле сервера разрешения конфликтов). Используйте следующую команду:
mmstartup -w quor001_s,mgmt001_s,...
- Запустите GPFS на всех вычислительных узлах с управляющего узла. Используйте следующую команду:
dsh -N ComputeNodes /usr/lpp/mmfs/bin/mmstartup.
- Проверьте состояние всех узлов, просматривая файл
/var/adm/log/mmfs.log.latest текущего менеджера файловой системы (обнаруживаемого при помощи команды mmlsmgr <filesystem>) и выводимую информацию из следующей команды: mmgetstate -w <nodenames> dsh -N ComputeNodes /usr/lpp/mmfs/bin/mmgetstate.
Этот метод может показаться чрезмерно предусмотрительным, но он выбран в качестве масштабируемого метода, который будет работать для очень большого кластера. Альтернативой указанному выше методу является использование команды mmstartup –a. Это работает для кластеров меньшего размера, но может пройти немало времени до возврата из команды для большого кластера, в котором узлы могут быть недоступны по различным причинам, например, при проблемах в сети.
Создание файловой системы GPFS
Для примера создается одна большая файловая система GPFS с использованием всех NSD, определенных для GPFS. Обратите внимание на то, что использованная команда, в отличие от указанной выше команды mmcrnsd, принимала в качестве аргумента измененные файлы дескрипторов дисков. Это требует объединения в один файл информации, выводимой на каждом шаге при создании NSD.
Пример кластера использует следующие настройки:
- Все NSD (устанавливается при помощи
-F).
- Точка монтирования:
/gpfs
- Автоматическое монтирование: yes (устанавливается при помощи
-A).
- Размер блока: 256KB (устанавливается при помощи
-B).
- Репликация: две копии данных и метаданных (устанавливается при помощи
-m, -M, -r, -R).
- Предположительное число узлов, монтирующих файловую систему 1200 (устанавливается при помощи
-n).
- Квоты разрешены (устанавливается при помощи
-Q).
Вот полная команда:
mmcrfs /gpfs /dev/gpfs -F disk_all.desc -A yes -B 256K -m 2 -M 2
-r 2 -R 2 -n
1200 -Q yes
|
В первый раз после создания /gpfs она монтируется вручную. Затем, с разрешенным параметром automount, она монтируется автоматически при запуске узлом GPFS.
Разрешение системы квот
Флаг -Q в приведенной выше команде mmcrfs разрешает использование квот (quotas) в файловой системе /gpfs. Квоты могут быть определены для отдельных пользователей или групп пользователей. Устанавливается также уровень квот по умолчанию, который применяется к каждому новому пользователю или группе. Квоты по умолчанию включаются при помощи команды mmdefquotaon. Изменяются квоты по умолчанию при помощи команды mmdefedquota. Эта команда открывает окно редактора, в котором можно указать их границы. Ниже приведен пример установки границ для квот:
gpfs: blocks in use: 0K, limits (soft = 1048576K, hard = 2097152K)
inodes in use: 0, limits (soft = 0, hard = 0)
|
Можно изменить отдельные квоты для пользователя или группы, используя команду mmedquota –u <username>. Пользователь может отобразить свою квоту при помощи команды mmlsquota. Пользователь superuser может отобразить состояние квот файловой системы при помощи команды mmrepquota gpfs.
Тонкая настройка
Данный кластер настроен так, чтобы GPFS запускался автоматически при каждой начальной загрузке сервера, путем добавления записи в /etc/inittab при помощи команды mmchconfig autoload=yes.
Используйте pagepool (пул страницы) GPFS для кэширования данных пользователя и метаданных файловой системы. Механизм pagepool позволяет GPFS реализовать запросы на чтение (а также запись) асинхронно. Увеличение размера pagepool увеличивает объем данных или метаданных, которые GPFS может кэшировать, не требуя синхронных операций ввода/вывода. Значением по умолчанию для pagepool является 64 MB. Максимальное значение GPFS pagepool равно 8 GB. Минимальное разрешенное значение равно 4 MB. На Linux-системах максимальный размер pagepool равен половине физической памяти компьютера.
Оптимальный размер pagepool зависит от требований приложения и эффективного кэширования его данных, к которым производится повторный доступ. Для систем с приложениями, обращающимися к большим файлам, повторно использующим данные, использующим преимущества функциональности GPFS предвыборки (prefetching) данных или работающим по схеме случайных операций ввода/вывода, увеличение значения pagepool может повысить эффективность. Однако, если значение слишком велико, GPFS не запустится.
Для нашего примера кластера используйте значение pagepool 512 MB для всех узлов в кластере.
Оптимизация при помощи сетевых настроек
Для оптимизации производительности сети и, следовательно, GPFS, разрешите jumbo-фреймы путем установки размера MTU для адаптера сети хранения данных в 9000. Оставьте параметр /proc/sys/net/ipv4/tcp_window_scaling разрешенным, поскольку это настройка по умолчанию. Настройки TCP-окна подгоняются при помощи CSM-сценариев во время установок, добавляющих следующие строки в файл /etc/sysctl.conf как на NSD-серверах, так и на NSD-клиентах:
# увеличить границы TCP-буфера Linux
net.core.rmem_max = 8388608
net.core.wmem_max = 8388608
# увеличить максимальные размеры и размеры по умолчанию TCP-буфера Linux
net.ipv4.tcp_rmem = 4096 262144 8388608
net.ipv4.tcp_wmem = 4096 262144 8388608
# увеличить max backlog, чтобы избежать пропущенных пакетов
net.core.netdev_max_backlog=2500
|
Настройка параметров DS4500
Настройки кэша сервера хранения данных при неправильной их установке могут повлиять на производительность GPFS. Пример использует следующие настройки контроллеров DS4500, рекомендованные в документации по GPFS:
- Read cache: enabled
- Read ahead multiplier: 0
- Write cache: disabled
- Write cache mirroring: disabled
- Cache block size: 16K
Заключение
Все! Вы должны были успешно установить большой Linux-кластер, следуя примеру из данной серии статей. Примените эти принципы для успешной установки вашего собственного большого Linux-кластера.
Ресурсы
Научиться
Получить продукты и технологии
Об авторе

Грэхем Уайт (Graham White) работает специалистом по системному управлению Linux Integration Centre в отделе Emerging Technology Services офиса IBM Hursley Park в Великобритании. Он имеет сертификат Red Hat Certified Engineer и специализируется на широком спектре технологий с открытым исходным кодом, открытых стандартах и технологиях IBM. В сферу его интересов входят LAMP, Linux, системы защиты, кластеризация и все аппаратные платформы IBM. Получил степень бакалавра по вычислительной технике и управлению с отличием в Exeter University в 2000 году.




